Think about the last time a data problem was identified before it became expensive. Who identified it?
In most organizations there is someone, or a small group of people, who are deeply embedded in the actual workflow, identifying the exact gaps that automated systems miss despite rarely appearing in official governance frameworks or data dictionaries. They have been in the data long enough to know when something is off, and they act on that knowledge before it becomes a downstream problem.
When AI enters the workflow, that changes. Their role is occasionally restructured, but more often they are moved out of the process entirely on the assumption that speed is an improvement on judgment, or they remain but are asked to review so many outputs so quickly that the review becomes a formality rather than a genuine quality check.
The workflow looks the same from the outside, but the layer that used to surface what the rules missed is no longer functioning the way it was.
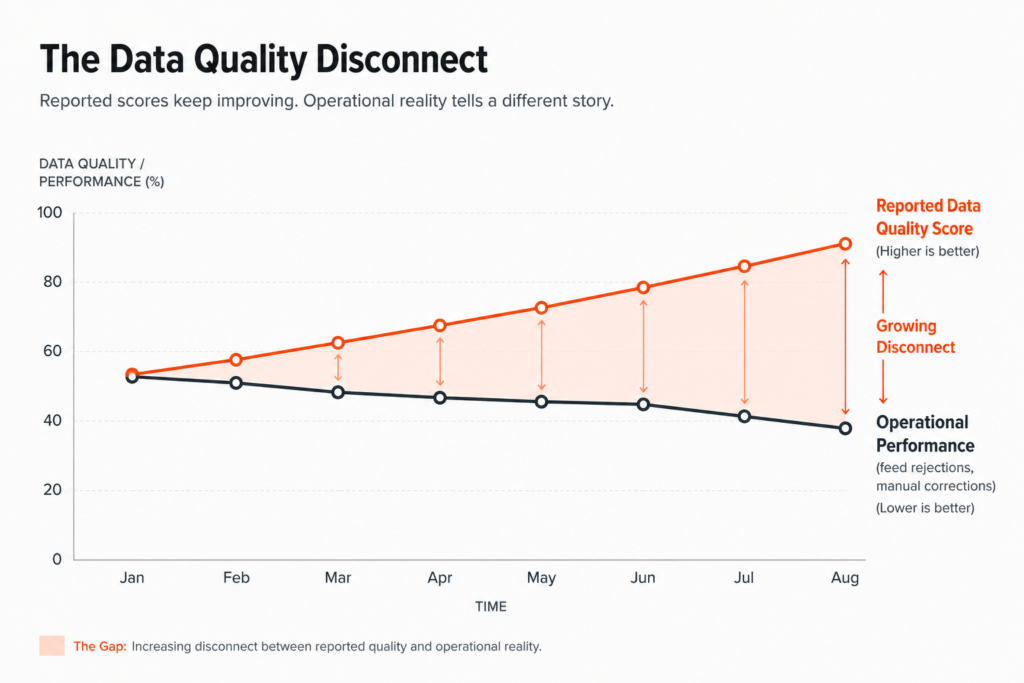
That is the gap most AI readiness assessments never account for, and it explains why an AI initiative can pass every data readiness check and still produce outcomes the business did not expect.
This blog covers one specific question most AI readiness assessments never ask: is the person who used to surface what the rules missed still in the process, and if they are, are they actually reviewing or just approving?
Key takeaways
- Most AI readiness assessments evaluate whether data is accurate, complete, and consistent, leaving aside whether the human judgment that used to surface what the rules missed is still functioning in the process.
- When AI replaces or accelerates a workflow, the human checkpoint that provided contextual correction often disappears with it, without anyone making a deliberate decision to remove it.
- An AI outcome can be wrong even when the data is technically accurate, because the outcome depends on the contextual layer the data was missing.
- The readiness standard your organization uses today was almost certainly built for a world where a human was still in the loop at the point where judgment mattered most.
- Genuine AI readiness requires a different kind of assessment, one that starts from what the AI system will do with the data rather than from what the internal system requires the data to be.
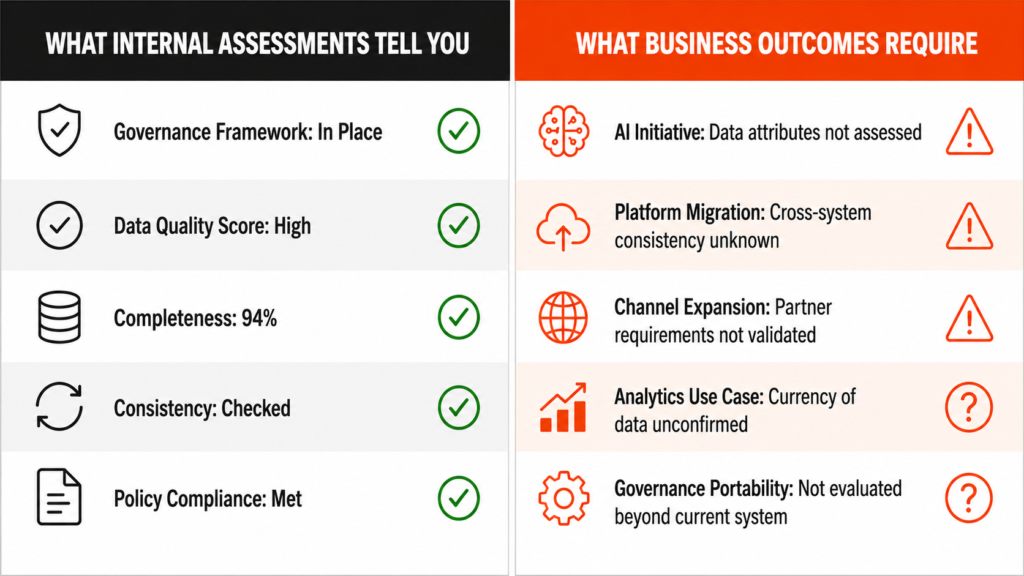
What AI Readiness Assessments Are Actually Checking
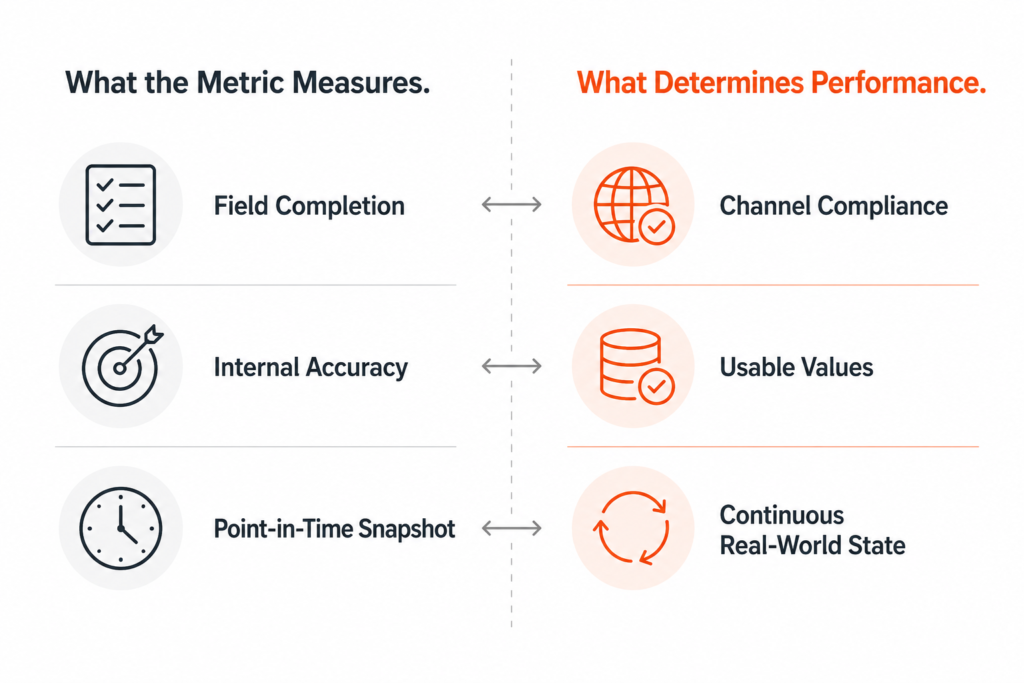
When most organizations assess whether their data is ready for AI, they evaluate it against accuracy, completeness, and consistency, covering whether the data matches a reference, the required fields are populated, and the values hold across systems. These dimensions were designed for a specific consumption model, one where data moves through a system, gets reviewed by a person, and the person’s judgment fills the gaps between what the rules enforce and what the business actually needs. In that model, a completeness check is meaningful because the reviewer will notice something missing and ask for it, while an accuracy check works because the person can flag a value that looks contextually wrong even if it is technically correct.
AI operates differently. The data moves through the system and the AI acts on what it sees, without the judgment or domain knowledge the human analyst used to supply, which means a completeness check only confirms that required fields are populated rather than confirming that the data contains the contextual signals the AI needs to produce a reliable output. The same limitation applies to accuracy — matching a reference does not tell you whether that reference reflects what the AI needs to make the right call in the specific situation it is processing.
Wait. Em dash still present in “The same limitation applies to accuracy — matching a reference.” Fix: “The same limitation applies to accuracy, since matching a reference does not tell you whether that reference reflects what the AI needs to make the right call in the specific situation it is processing.”
This is where most readiness frameworks stop short, and it is precisely what Accenture Research’s 2026 study on AI-ready data confirmed when surveying 2,000 organizations deploying advanced AI. Data readiness emerged as the most frequently cited barrier to AI value, with most organizations applying frameworks that predate the specific demands of agentic and advanced AI systems. The assessment was designed for one consumption model, and AI operates in a different one. What that difference costs an organization when it goes unexamined is more specific than most readiness frameworks were built to detect.
“Data readiness is the most frequently cited barrier to AI value. Most organizations are applying readiness frameworks that predate the specific demands of advanced AI systems.”
– Accenture Research, AI-Ready Data for Advanced AI, 2026
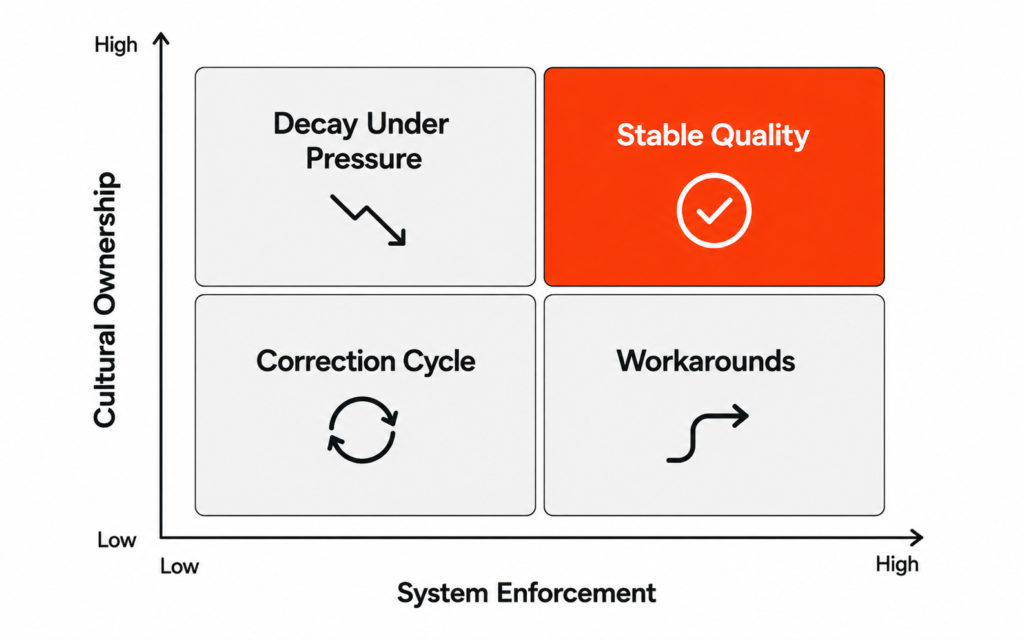
The Human Checkpoint Most Assessments Never Evaluate
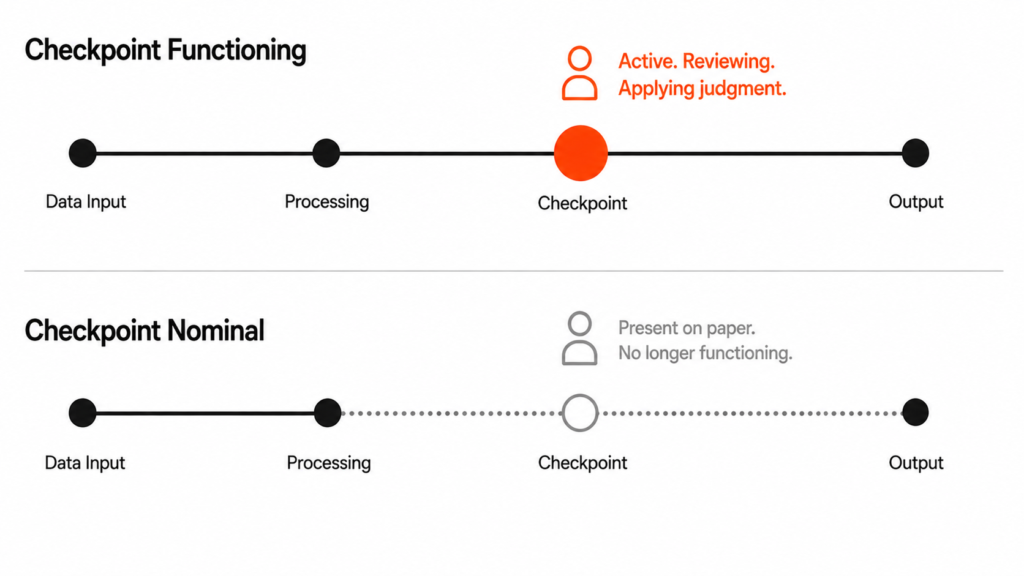
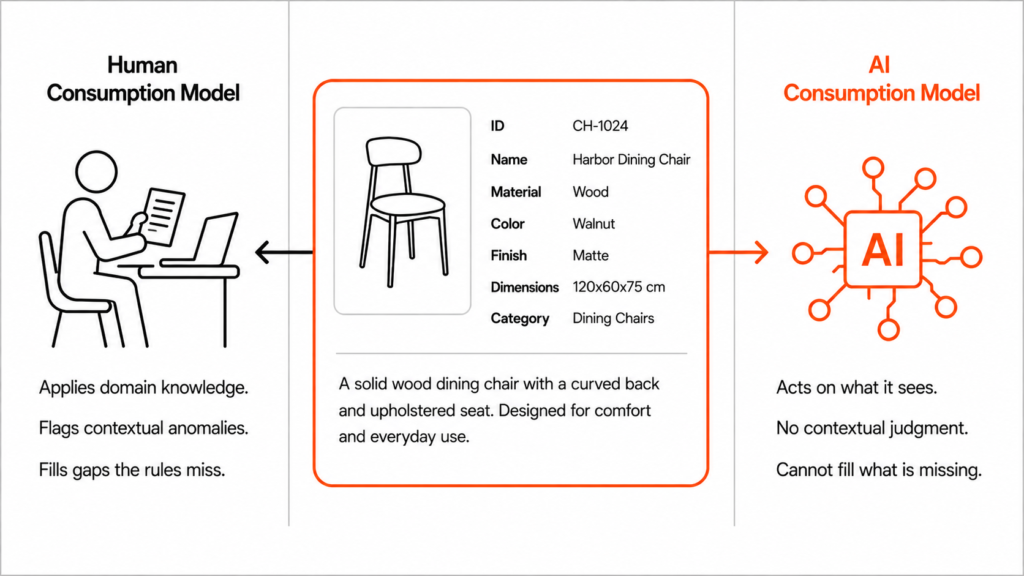
Every data workflow has moments where a human used to look at what the system produced and apply something the system could not supply independently: domain knowledge, business context, and pattern recognition built from years of seeing what the data means in practice.
Although this checkpoint rarely appeared in governance frameworks or data dictionaries as a formal quality control step, it functioned as one because the person running it had enough context to identify what the rules missed, consistently, before problems reached downstream.
When AI enters the workflow, that person’s role changes in ways that are rarely planned deliberately. Their position is occasionally restructured, but more often they are moved out of the process entirely on the assumption that AI speed is an improvement on human judgment, or they remain while being asked to review so many outputs so quickly that the review becomes a signature rather than a genuine evaluation.
This is the dynamic MIT Sloan Management Review captured in its research on agentic AI, drawing on what leaders have learned from early deployments. The research found that human-in-the-loop oversight frequently becomes performative, with people asked to approve so many things so fast that they do not genuinely engage with what they are approving, leaving a checkpoint that still exists on paper but has stopped functioning as one.
“Human-in-the-loop oversight frequently becomes performative. People are asked to approve so many things so fast that they do not really engage with what they are approving. The checkpoint still exists on paper but has stopped functioning as one.”
— MIT Sloan Management Review, Agentic AI: What Leaders Wish They Knew Sooner
What that describes is a process design failure of exactly the kind a standard data readiness assessment was never built to surface, and by the time it becomes visible, the cost of addressing it has already grown significantly.
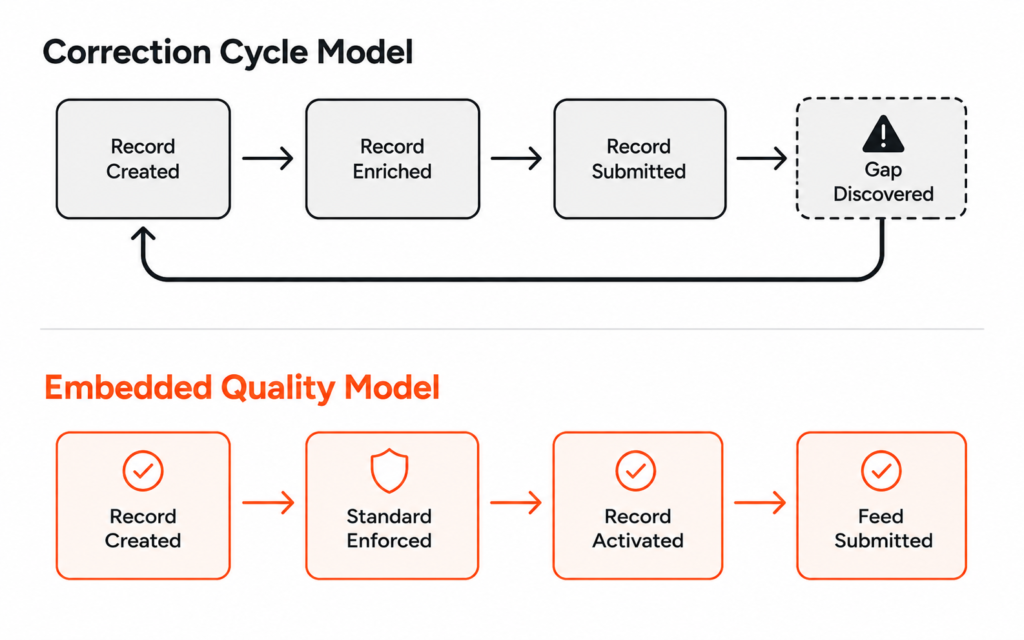
What Happens When the Checkpoint Disappears

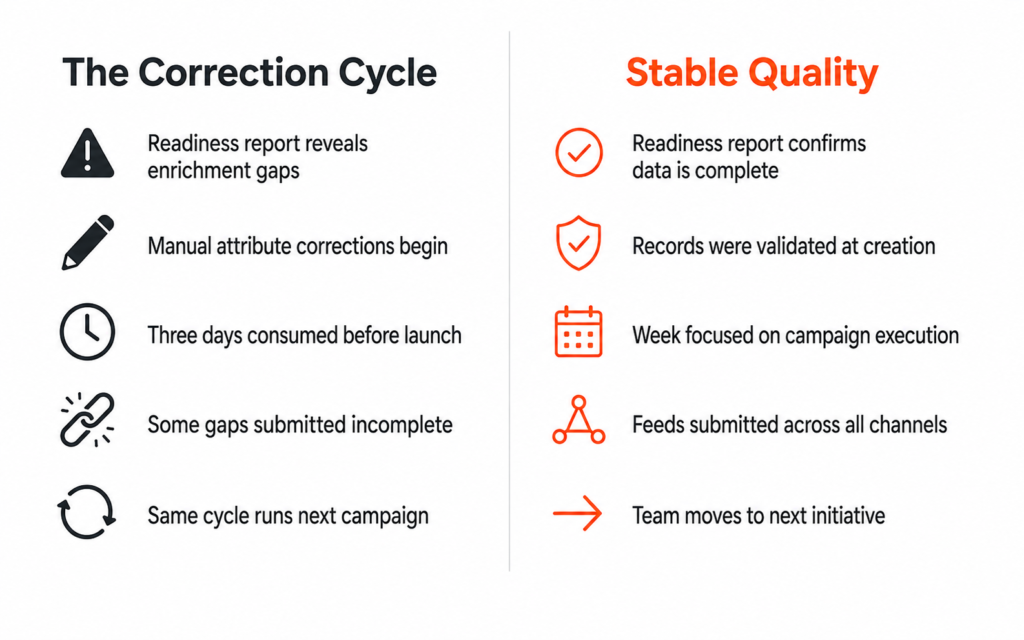
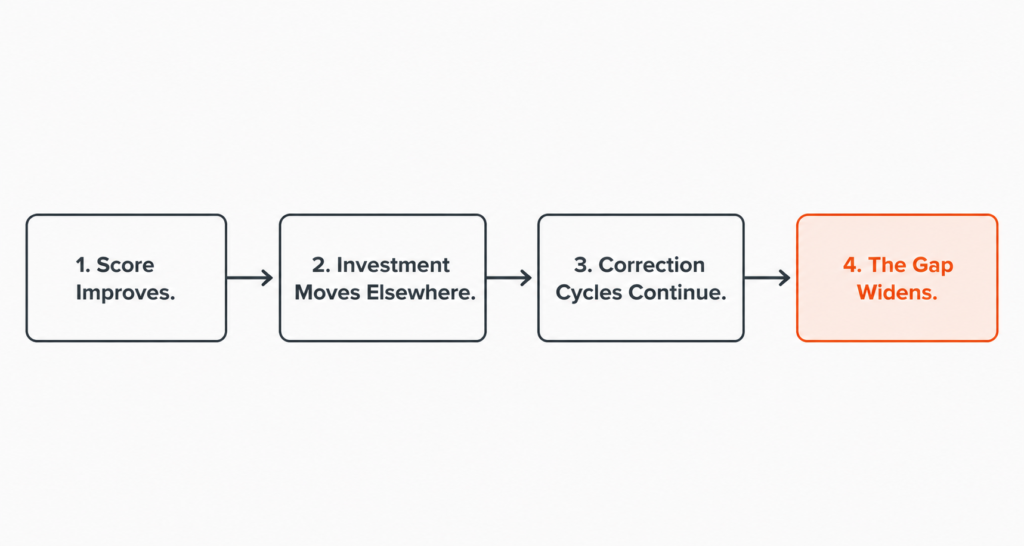
The consequences of removing the human checkpoint are not always immediate, which is part of what makes this failure mode so difficult to detect and so expensive to correct.
The AI produces outputs, the outputs look correct, the metrics improve, and the initiative is declared a success before the team moves on to the next use case.
The gap surfaces later, when a pattern the human would have identified has been running long enough to produce a decision, a recommendation, or an output that the business has already acted on. By that point the cost of correction is significantly higher than the cost of maintaining the checkpoint would have been, and the connection between the missing checkpoint and the downstream consequence is rarely made because too much time has passed between the two events.
This is what Forrester’s research on the state of agentic AI in 2026 identified as a structural pattern rather than an isolated incident. The research found that agents bolted onto workflows built for human pace produce only task savings, and that genuine value requires rebuilding roles and approval structures around autonomy rather than attaching automation to a process still designed around manual review. The organizations that have captured AI value are those that redesigned the workflow around what the AI actually needs to perform reliably, including identifying where human judgment needs to remain, in what form, and at what frequency.
“Agents bolted onto workflows built for human pace produce only task savings. Real value requires rebuilding roles and approval structures around autonomy rather than attaching automation to a process still designed around manual review.”
— Forrester, The State of Agentic AI in 2026
The readiness failure in these cases is structural rather than technical, and it remains invisible to standard readiness assessments because those assessments were built to check the data rather than the process the data moves through, and that distinction points directly to how the standard itself was designed.
Why the Readiness Standard Wasn’t Built for This
The readiness standard most organizations apply to AI initiatives was built for a specific world, one where data moves through a system, a person reviews what comes out, and that person’s judgment is the last quality gate before the output reaches a decision.
In that world, accuracy, completeness, and consistency are the right dimensions to assess because they ensure the data is in the right shape for the person reviewing it, and the person does the rest. AI changed what the rest means. Without a person automatically in the loop, the AI acts on what it sees, without questioning contextually suspicious values, applying domain knowledge, or flagging data that reflects a state of the business that has already changed.
The readiness standard was built for a world where the human checkpoint was a given, and in an AI-first workflow the checkpoint becomes a deliberate design decision rather than an assumed constant. Most organizations are applying a framework designed before AI changed what readiness required, which is a failure of timing rather than intention, and the organizations that close this gap will do so by extending their existing framework to cover the dimensions the original design never needed to address.
What AI Readiness Actually Requires Now
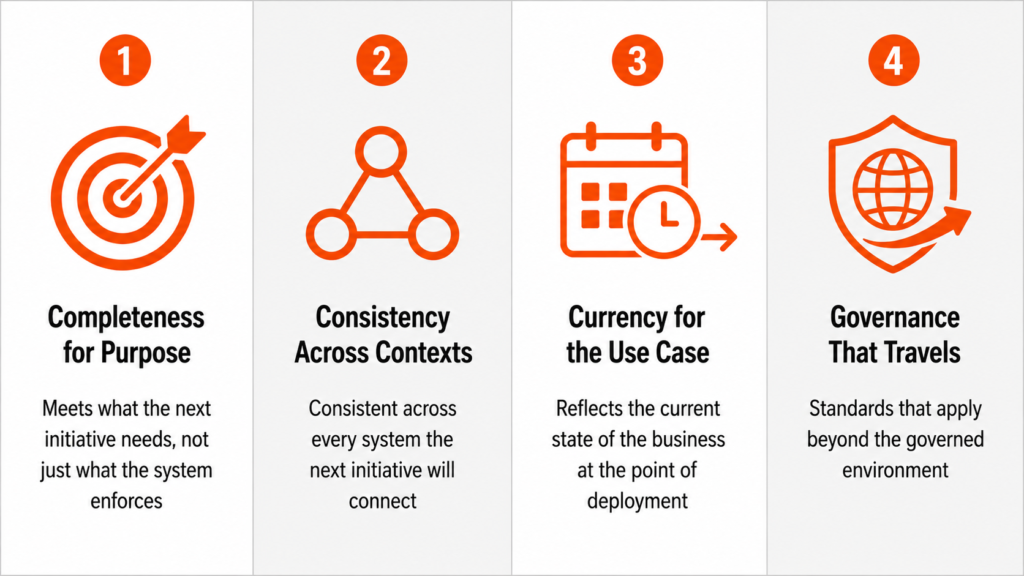
Genuine AI readiness extends the existing standard rather than replacing it, covering the dimensions the original framework never needed to address because a human was always there to fill them in. Four of those dimensions are worth examining specifically, because none of them appear in a standard completeness, accuracy, and consistency assessment, and all of them determine whether an AI initiative delivers what the business expects.
- Contextual completeness. The AI needs more than populated fields, specifically the contextual signals that tell it how to interpret what it is seeing. A product record can be 100% complete against internal thresholds and still lack the attributes an AI personalization engine needs to make the right recommendation for a specific customer segment, because the internal threshold was defined for a human reviewer who would supply that context from memory.
- Decision-point coverage. Mapping the points in the workflow where a human used to apply judgment, and evaluating whether the data at each of those points contains enough information for the AI to make the same call reliably, is a different exercise from checking whether the data is accurate and complete. Most readiness assessments do not attempt it.
- Drift sensitivity. Data that was accurate at the point of assessment may reflect a state of the business that has already changed by the time the AI acts on it, and the question worth asking is how quickly the data drifts relative to the AI’s update cycle. If the drift is faster than the cycle, the AI is consistently acting on a version of reality that no longer exists.
- Checkpoint audit. Where in the workflow did a person used to surface what the rules missed, is that person still in the process, and if they are, are they genuinely reviewing or nominally approving? The checkpoint audit is the dimension most organizations have never formally conducted because it never needed to be an assessment step when the human was always there.
Understanding these four dimensions is the starting point, and knowing which of them your current standard already covers is what separates an organization that is genuinely ready from one that believes it is.
How to Know Whether Your Standard Has Kept Pace
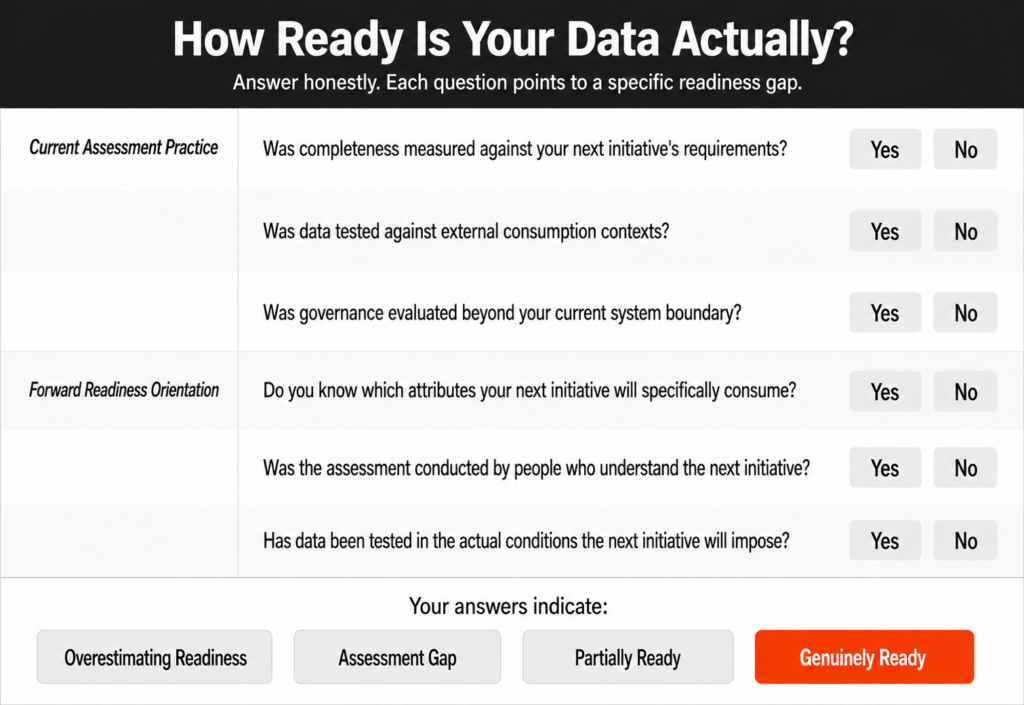
Before extending an existing readiness framework to cover an AI initiative, four questions are worth answering honestly. They are not designed to produce a score. They are designed to surface where the standard has stopped keeping pace with what the AI initiative actually requires.
- Was your readiness standard designed before your organization began using AI to consume the data it governs? A standard that predates the AI initiative it is now being applied to was almost certainly designed for a human consumption model, which makes it incomplete for what AI actually requires.
- Does your readiness assessment evaluate whether the human checkpoints in the workflow are genuinely functioning? A checkpoint that exists on paper but processes approvals too quickly for genuine engagement is functioning as a formality rather than a quality gate, and a readiness assessment that cannot distinguish between the two is missing the most critical quality layer in an AI workflow.
- Has your readiness standard been updated since the last significant change to how the data is consumed? Every time a new AI model is deployed, a new platform is implemented, or a new use case is activated, the consumption model changes, and the readiness standard needs to change with it. Most organizations update their data while leaving the framework they use to assess it unchanged, which means the standard is almost always lagging behind the current deployment.
- Do the people who designed your readiness standard understand what the AI system consuming the data actually does with it? If the consumption model has changed, if AI is now doing what a person used to do, the people responsible for the readiness standard need to understand the new model well enough to assess whether the data genuinely supports it, rather than assessing it against a model that no longer reflects how the data is used.
If the honest answer to any of these is no, your readiness standard has not kept pace with what your AI initiative will demand from the data, and the gap between what the standard checks and what AI actually needs is where the initiative’s most expensive surprises are waiting.
Before your next AI initiative extends your existing readiness framework to cover something it was never designed to assess, the question worth answering is whether the standard itself is ready for what AI actually requires, beyond whether the data meets the standard you already have.
That is the assessment ThoughtSpark helps enterprise data and AI teams conduct, identifying the specific distance between the readiness framework you have and the one your AI initiative actually needs, and building the path between the two.