

Your organization has probably invested significantly in data readiness.
A governance program. A platform migration. A data quality initiative. Possibly all three. The dashboards are improving. The CDO has a seat at the leadership table. The data strategy is documented and aligned to the technology roadmap.
And yet, when a new AI initiative, a major platform decision, or a channel expansion needs your data to perform, something is not quite ready.
That experience, of believing you are prepared and then discovering you are not, is not a failure of execution. It is a symptom of how most organizations define and measure data readiness, and that definition is almost always measuring the wrong thing.
Key takeaways
- Most organizations assess data readiness against internal standards — whether their data meets the requirements of the systems that store it — not against what the business needs the data to actually do next.
- The IBM Institute for Business Value found that 81% of CDOs say their data strategy is integrated with their technology roadmap, yet only 26% are confident their data can support AI-enabled revenue streams. That 55-point gap is what overestimation looks like at scale.
- Overestimation happens in three specific ways: confusing governance with readiness, confusing clean data with usable data, and confusing historical readiness with forward readiness.
- Genuine data readiness is not a milestone you reach. It is a continuous assessment of whether your data can support the specific outcomes your organization is building toward next.
- The question worth asking before your next platform decision, AI initiative, or channel expansion is not whether your data passed the last quality review. It is whether your data is ready for what comes next.
Why Data Readiness Is Harder to Assess Than Most Organizations Realize
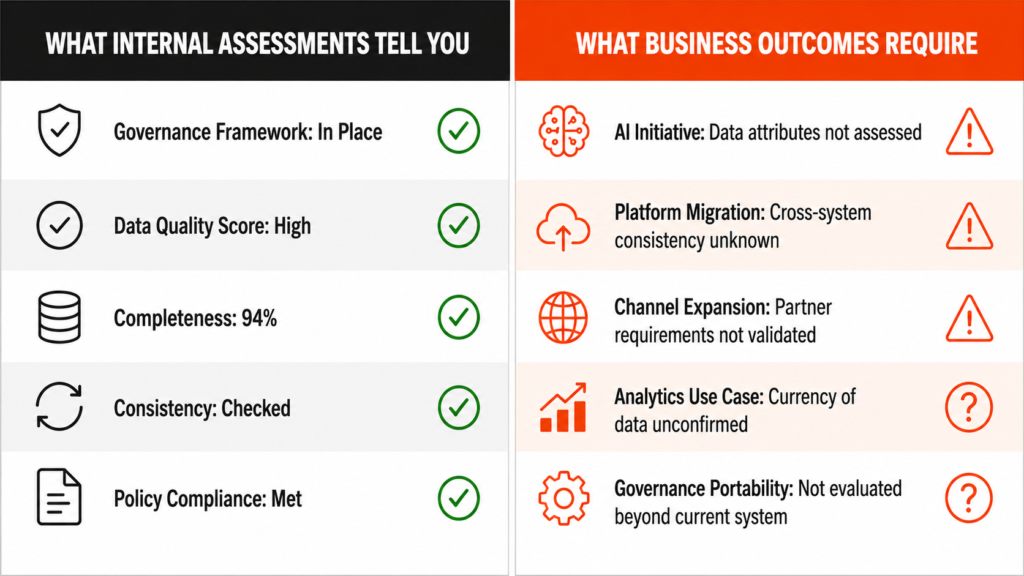
Most Organizations assess data readiness using the tools they already have — quality dashboards, governance audit results, platform implementation reports, completeness scores. These tools measure internal conditions accurately, and the problem is that internal conditions are not what determines whether data performs when the business needs it to.
A governance audit tells you whether your framework is in place. It does not tell you whether the data that framework governs is fit for the specific initiative you are about to commit to. A quality dashboard tells you whether your data meets the thresholds you defined when you built the measurement system, and it does not tell you whether those thresholds reflect what your next AI model, your next platform, or your next channel partner actually requires.
The assessment looks healthy because it was designed to look healthy against the standards it was built to measure, and the gap between those standards and what the business actually needs the data to do is where the overestimation lives.
The IBM Institute for Business Value's 2025 CDO study, based on 1,700 senior data leaders across 27 geographies, found that 81% of CDOs report their data strategy is integrated with their technology roadmap, while only 26% are confident their data can support new AI-enabled revenue streams. That 55-point gap between strategic alignment and operational confidence is not a coincidence, and it is what happens when Organizations measure readiness against internal strategy alignment rather than against what specific business outcomes actually demand from the data.
"81% of CDOs report their data strategy is integrated with their technology roadmap. Only 26% are confident their data can support new AI-enabled revenue streams. That 55-point gap is what overestimation looks like at scale."
— IBM Institute for Business Value, 2025 CDO Study
The Three Ways Organizations Overestimate Their Data Readiness

Overestimation is not a single failure. It happens in three specific and distinct ways, and most Organizations are experiencing at least one of them without recognizing it as overestimation rather than simply as an unexpected gap.
Overestimation 1: Confusing Governance With Readiness
Having a governance framework is not the same as having data that is ready to perform. Governance defines the standard, and readiness means the data meets that standard in the specific context where it needs to be used.
Most governance assessments evaluate whether the framework exists — whether ownership is assigned, whether policies are documented, whether quality controls are in place — and they do not evaluate whether the data the framework governs is actually fit for the next initiative the business is about to build on top of it.
A governance Program that was designed to improve data consistency for internal reporting may produce data that is entirely consistent for that purpose and still inadequate for an AI initiative that requires different attribute completeness, different taxonomy consistency, or different cross-system coherence than the governance framework was ever designed to enforce.
The governance is real. The readiness it implies for the next use case may not be.
Overestimation 2: Confusing Clean Data With Usable Data
Data that passes internal quality checks is clean against the internal standard, and it is not necessarily usable for the purpose the next initiative requires.
A product catalogue that is 94% complete against internal thresholds may be significantly less complete against the specific requirements of an AI personalisation engine, a new retail channel, or a marketplace expansion, because the internal threshold was defined to reflect what the internal system needs while the external requirement reflects what the channel, the partner, or the AI model actually consumes.
In each case the completeness score reflects what was defined as quality when the measurement system was built, and the operational consequence reflects what the next initiative actually needs from the data — which is why the score can look healthy while the readiness gap remains significant.
Overestimation 3: Confusing Historical Readiness With Forward Readiness
A data quality assessment tells you how ready your data is today against the standards you defined in the past, and it does not tell you how ready your data is for what you are planning to build next.
The next AI initiative, the next platform migration, the next channel expansion, and the next market entry will each make specific demands on your data that your current assessment was never designed to evaluate. The question the assessment answered was whether your data is ready for what you are already doing, and the question that determines whether your next initiative succeeds is whether your data is ready for what you have not yet built.
A backward-looking metric tells you where you were. Genuine forward readiness requires asking specifically what the next initiative needs from your data and evaluating honestly whether the data can deliver it before the initiative has already committed to a timeline that assumes it can.
The Cost of Getting the Assessment Wrong
The consequences of overestimating data readiness are not always immediately visible, which is part of what makes the overestimation so persistent. The initiative launches, the platform goes live, and the AI model gets deployed, and the gaps in the data do not announce themselves as data readiness failures. They present as performance problems, as unexpected manual workloads, as AI outputs that do not match projections, and as channel launches that take longer than planned.
By the time the data readiness gap becomes undeniable, the initiative has already committed its timeline, its budget, and its leadership credibility to the assumption that the data was ready, and the cost of correcting the gap at that point is significantly higher than the cost of identifying it before the initiative began.
McKinsey's research on AI data readiness found that more than two-thirds of high-performing companies identify data as the primary obstacle for enabling AI, and only 7% of companies have fully scaled AI across their Organizations. The Organizations that have scaled successfully are the ones that assessed what their AI initiatives actually needed from the data before committing to the initiative, and closed the gaps they found before the initiative depended on data that was not yet ready to support it.
"More than two-thirds of high-performing companies say data is the primary obstacle for enabling AI. Only 7% of companies have fully scaled AI across their Organizations."
— McKinsey, AI Data Readiness: The Key to Scaling Impact, June 2026
The cost of overestimation is not just delayed ROI. It is the accumulated cost of initiatives that underperform because the data foundation they assumed was ready was not prepared for what the initiative actually demanded. Most data projects do not fail at implementation. They fail before the first line of code because the data was never genuinely ready for what the project required of it.
What Genuine Data Readiness Actually Requires
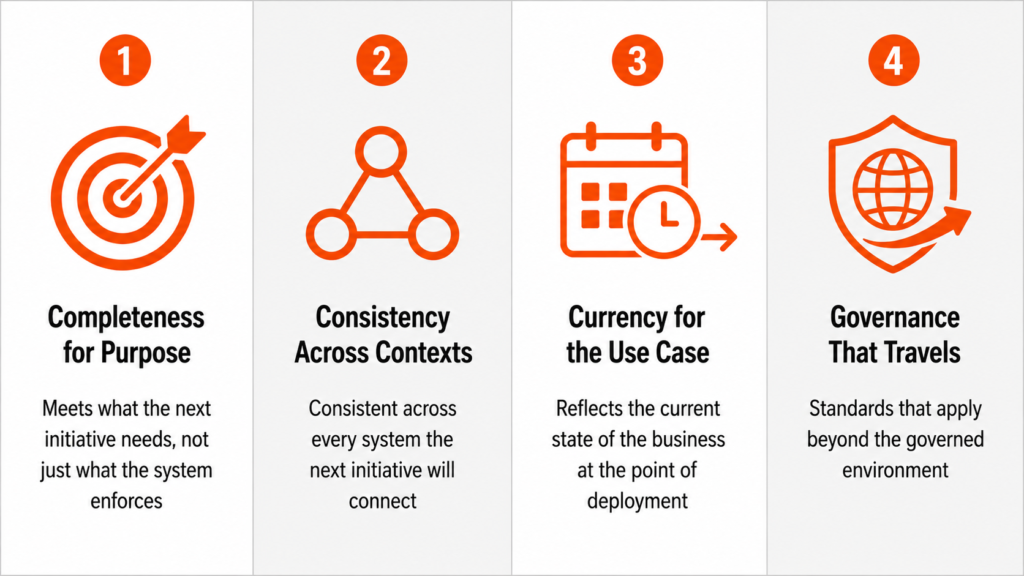
Genuine data readiness is not a status you achieve by completing a governance Program or passing a quality audit. It is a continuous assessment of whether your data can support the specific outcomes your organization is building toward, and it has four dimensions that most internal assessments do not capture.
Completeness for purpose, not completeness for the system.
Internal completeness measures whether required fields are populated against the thresholds the system was configured to enforce, and completeness for purpose measures whether the data contains what the next initiative specifically needs — the attributes an AI model will consume, the fields a new channel requires, the data points a platform migration will need to carry cleanly across systems. The threshold that matters is the one your next initiative depends on, and that threshold is rarely the same as the one your system currently enforces.
Consistency across contexts, not just within systems.
Data that is internally consistent within one system may be inconsistent across the systems a new initiative needs to connect, and cross-system consistency — the same entity described the same way in the PIM, the ERP, the commerce platform, and the analytics layer — is what enables new initiatives to work with your data as it exists rather than requiring a cleaning and normalisation project before the initiative can begin. Most quality assessments evaluate consistency within a system, and genuine readiness requires evaluating it across every system the next initiative will touch.
Currency for the use case, not just accuracy at the last assessment point.
Data that was accurate and current when the last assessment was conducted may have drifted since then, and the next initiative will work with your data as it is at the moment of deployment rather than as it was at the moment of the last review. Currency for the use case means the data reflects the current state of the business in the specific dimensions the next initiative depends on, assessed at the point of deployment rather than at the point of governance review.
Governance that travels with the data.
Governance frameworks typically govern data within a defined system or domain, and genuine readiness means the governance standards travel with the data as it moves between systems, is consumed by new tools, and is used in new contexts. When data leaves a governed environment and enters an AI model, a new platform, or a partner integration, the governance constraints that made it trustworthy in the original context need to apply in the new one, and most governance assessments do not evaluate whether the framework performs beyond the boundary it was built to govern.
How to Know Whether Your Data Is Actually Ready
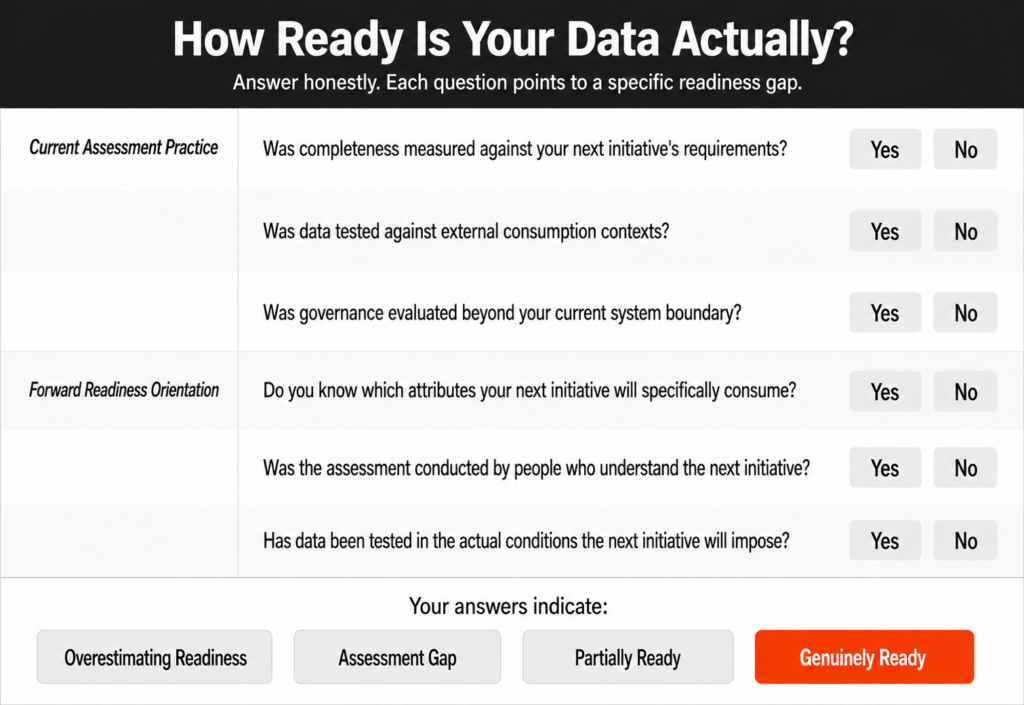
Before committing to the timeline and budget of your next major initiative, these six questions will tell you more about your actual data readiness than any internal quality dashboard will.
On your current assessment practice:
Was the completeness threshold your last data quality assessment measured against defined by the requirements of your next initiative, or by the requirements of your current system?
Was your data tested against external consumption contexts — the AI model, the channel partner, the platform — or against internal storage and processing standards?
Was your governance framework evaluated for how it performs when your data moves between systems and is consumed by tools and partners outside the governed environment?
On your forward readiness orientation:
Do you know specifically which data attributes your next AI initiative, platform migration, or channel expansion will consume, and have you assessed whether your data delivers them at the quality level required?
Was your last data readiness assessment conducted by people who understand both the data estate and the specific business initiative it is supposed to support?
Has your data been tested in the actual conditions the next initiative will impose, rather than in a controlled assessment environment built against internal standards?
If your honest answers reveal that your assessments were defined against current system requirements rather than forward initiative requirements, and that your data has not been tested against the specific conditions the next initiative will impose, the gap between your reported readiness and your actual readiness is worth understanding before you commit to the next initiative's timeline.
What Closing the Gap Looks Like in Practice
The Organizations that have moved from overestimating data readiness to genuinely achieving it did not do it by running better assessments of the same kind. They changed what the assessment was designed to answer.
They assessed readiness forward, not backward.
Starting from what the next initiative needs and working back to the data. That shift in direction changes every question the assessment asks, moving from "is our data clean?" to "is our data clean enough for what this initiative specifically requires?"
They tested data against external consumption contexts.
Running the data through the actual conditions the next initiative will impose before committing to the initiative timeline — the AI model consuming the actual data, the channel partner receiving the actual feed, the platform ingesting the actual records. The gaps that surface in this test are the gaps that would have appeared at deployment, surfaced early enough to close them before they cost anything beyond the time to fix them.
They made readiness assessment a continuous practice.
Moving from a pre-project checklist completed once before the initiative launches toward an ongoing evaluation of whether the data estate is keeping pace with what the business is building toward. As the business adds new products, enters new markets, adopts new platforms, and pursues new AI use cases, the readiness question changes, and the Organizations that stay genuinely ready are the ones that keep asking it rather than relying on the answer from the last time they asked.
Before your next platform decision, AI initiative, or channel expansion, the question worth answering is not whether your data passed the last quality review. It is whether your data is genuinely ready for what comes next.
That is the assessment ThoughtSpark helps enterprise data and commerce teams conduct and act on. The Data Readiness Hub is where that conversation starts, identifying the specific distance between where your data currently performs and where your next initiative needs it to perform, and building the path between the two.